[Paper Review] Personalized Federated Learning with Clustering: Non-IID Heart Rate Variability Data Application
.
안녕하세요. 에이치비킴 입니다.
이번 논문 리뷰는 논문이 작성된 포맷에 맞춰 순서대로 살펴 볼 예정입니다.
논문명: Personalized Federated Learning with Clustering: Non-IID Heart Rate Variability Data Applicaiton (Joo Hun Yoo et al.)
0. ABSTRACT
@ 머신러닝 기법은 큰 데이터셋 내부에서 연관성을 찾는데 유용하게 쓰인다.
@ 하지만 데이터를 수집하고 활용하는 과정에서 privacy 문제가 제기될 수 있다. 의료 데이터와 같이 공개하기에 민감한 데이터는 특히 그렇다.
@ 이러한 측면에서, 연합학습 기법이 privacy 보호 측면에서 장점을 갖는다.
@ 위 privacy에 포함될 수 있는 분야는 다음과 같다. (환자의 정보가 포함되어 있는 healthcare field)
@ 그러나, 의료 데이터의 분포가 Independent and Identically Distributed (IID)하는 것은 현실적이지 못하다.
@ 그리고 이는, 이상적이지 않은 데이터 분포 형태로써 학습 데이터로 활용하기에 적합하지 않다.
@ 본 논문에서는, 심박수에 따른 우울증 검출을 위한 Personalized Federated Cluster Models를 제안한다.
@ 환자들이 더 많은 각자의 모델을 가질수록, non-IID한 상황에서 더 높은 accuracy를 보인다.
1. INTRODUCTION
- 분류 1
@ 머신러닝 기법은 많은 양의 데이터 속에 담긴 유의미한 정보를 찾아내기 위해 많은 분야에서 사용된다.
@ 딥러닝 기법은 서로 독립적인 데이터셋에서 복잡한 관계를 찾아내기 위해 사용된다. (인간이 수행하기에는 큰 시간이 소요되는 업무를 수행)
@ 머신러닝과 딥러닝 기법 모두, 활용하기 위해서는 매우 많은 양의 데이터가 필요하다.
@ 현재, EU's General Data Protection Regulation (GDPR), California Consumer Privacy Act (CCPA), and China's Cyber Security Law (CSL) 등과 같은 많은 단체에서 data privacy 보호를 위한 규제를 강화하고 있다.
@ 연합학습은 decentralized한 데이터 분포 구조를 갖으며, 이는 data collection에 의지하지 않는다는 의미로서 data privacy의 유출 없이 사용가능한 기법이다.
@ 본 논문에서는, non-IID한 상황에서의 성능이 개선된 연합학습을 활용하여 Major Depressive Disorder (MDD) severity를 예측한다.
- 분류 2
@ MDD 는 지난 2주 동안의 감정을 분석하여 mental disorder를 검사하는 방법이다.
@ 우울증 검사는 Hamilton Depression (HAM-D), Montgomery-Asberg Depression Rating Scale (MADRS), and Beck's Depression Inventory (BDI) 등을 통한 수치적 분석과, 정신의학과에서의 상담을 통해 이루어진다.
@ 하지만 위와 같은 진단법은 굉장한 시간적 자원을 쏟아야 한다.
@ 때문에 연구자들은 Electroencephalogram (EEG), and Heart Rate Varibaility (HRV)와 같은 biomarkers를 이용하여 MDD를 진단하고자 한다.
@ 본 논문에서는 data collection cost가 낮고, 활용하기가 단순한 HRV 데이터를 사용한다.
@ Clustering은 non-IID 환경에서의 연합학습 한계를 극복하기 위해 사용한다.
2. BACKGROUND & RELATED WORKS
- Federated Learning and Clustering Methods
연합학습(Federated Learning) 이란?
. 안녕하세요, 에이치비킴 입니다. 연합학습에 대해서 본격적으로 살펴보기 전에, 연합학습이 최근 각광받고 있는 이유가 무엇인지 알아보아야겠죠. 연합학습은, 기존의 머신러닝 기법들과는
hyungbinklm.tistory.com
@ 기존의 연합학습 기법은, non-IID한 데이터 분포 상황에서 최적의 솔루션을 제공하지 못한다.
- HRV data for Major Depressive Disorder Diagnosis
@ HRV 데이터는 우울증 증상과의 눈에 띄는 상관 관계에 의해서 최근 우울증 진단의 기준으로 활용되기도 한다.
@ HRV 데이터를 활용한 이전 연구에서는 main ML 알고리즘으로 Support Vector Machine with feature selection (SVM-RFE)를 사용하였다.
@ 또한, 이전 연구에서는 우울증/비우울증 으로 이진 분류만 진행되었다. 본 연구에서는 non-binary nature를 분석한다.
@ 결정적으로, 이전 연구들은 privacy regulation에 대한 문제를 고려하지 않았다.
3. PERSONALIZED FEDERATED CLUSTER MODEL
- Dataset
@ 삼성 의료 센터 정신의학과의 HRV 데이터를 수집하였다. (대조군을 포함하여 총 100명의 피험자를 12주간 추적 관찰한 데이터이며, 그들의 HRV 매개변수는 baseline, stress, recovery 3단계로 측정하였다.)
@ 본 논문의 목적은 HRV 데이터와 우울증 심각성의 complex relations를 찾아내는 것이기에, 여타 mental health scores는 데이터셋에 포함시키지 않았다.
@ HRV 데이터와 간단한 biomarker 데이터를 입력 데이터로 사용하였다.
@ MDD severity의 타겟 지표로 0-50 사이의 HAM-D를 사용했다.
@ 과학적 증명에 따라 HAM-D 값을 normal, mild, moderate-severe 3단계로 구분하였다.
- Preprocessing
@ HRV 데이터는 479개의 행과 80개의 열로 구성되어 있다.
@ zero values로 dummy column을 추가하여 총 81개의 열이 되게끔 만든다.
@ 81개의 열을 9x9 parameter map으로 제작하여 총 479개의 map이 만들어지게끔 구성한다.
- Tesing Procedure
@ 훈련 진행은 기존 연합학습과 동일하다고 보여진다. (본 논문에서 제안하는 클러스터링 알고리즘은 아래 그림 1을 참고)

@ 새로운 클라이언트가 들어오면, FindNearestCluster(cosine similarity metric 기반)을 적용하여 기존의 클러스터 모델 중 가장 유사한 모델로 클러스터링한다.
@ PFCM 기법은 등록 시에만 적용되며, 클러스터링된 이후에는 기존의 연합학습처럼 동작한다.
@ 각 모델의 accuracy는 최종 성능 검증을 위해 평균화된다.
4. EXPERIMENT
@ 본 논문에서 분류를 위해 설정한 클래스는 3개 이다.
@ Train set/Test set ratio - 80/20
@ 성능 비교를 위해 다음과 같은 기법들을 사용하였다.
- FedAvg
- Support Vector Machine(SVM), disregarding privacy
- Support Vector Machine with Recursive Feature Elimination(SVM-RFE), disregarding privacy
@ 성능 비교는 그림 2를 통해 확인 할 수 있다.
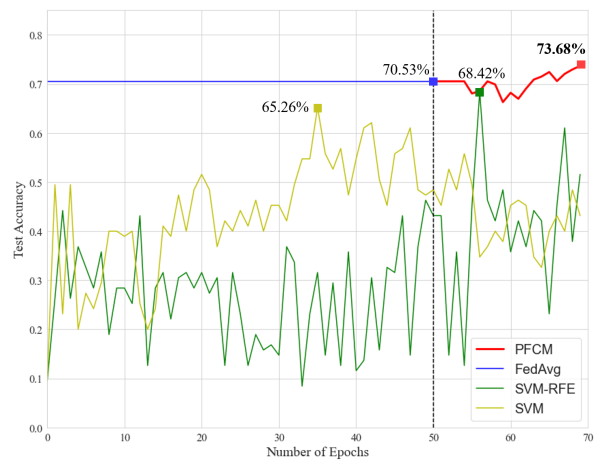
@ 그림 2를 통해 다른 기법에 비해 성능이 뛰어남을 확인 할 수 있다.
@ 73.68%라는 수치는 3개의 클래스로 분류하였을 때이며, 2개의 클래스로 분류할 때에는 90.70%의 accuracy 성능을 보인다.
5. CONCLUSION
@ 연합학습과 클러스터링의 접목을 통하여 기존의 머신러닝 기법 성능에 비해 능가하는 성능을 보였다.
@ 연합학습은 기존의 머신러닝 기법과 다르게 엄격한 data privacy regulation을 준수한다.